


Hudi Newsletter#8: October-2024


Hello, Apache Hudi Community!
Welcome to the October edition of the Hudi newsletter, brought to you by Onehouse.ai.
Exciting news! The Hudi team has announced the very first edition of the Apache Hudi: The Definitive Guide. Whether you've been using Hudi for years, or you’re new to Hudi’s capabilities, this guide will help you build robust, open, and high-performing data lakehouses.

The best part? Two chapters of the book are already out as part of the early release! Get them here and share your feedback!
Community Events
October was an Event-ful Month on the Community side! There were so many amazing talks centered around Apache Hudi.

In this community sync talk, Shopee's Expert Engineer presented their approach to optimizing real-time queries on massive datasets while reducing data ingestion costs. They shared how they have implemented key innovations to their current architecture with Apache Hudi.
Some of the key highlights from their new architecture with Hudi:
Achieved data freshness within 10 minutes.
Reduced point query latency to just 5 seconds.
Drove a 200% reduction in data ingestion costs.

Last month the Hudi Community started a brand new series “Lakehouse Chronicles with Apache Hudi” with everything focused around open source Hudi. Episode 1 started off with an introduction to some of the important concepts in Hudi and provided a hands-on guide for data engineers to get started with Hudi and Spark SQL. In Episode 2, Albert Wong (Solutions Engineer at Onehouse) presented his docker demo on how to ingest data in batches using HudiStreamer from Kafka, use multiple compute engines like Spark and Trino, execute compaction on Merge-on-Read tables, etc for Hudi tables.
Both of these episodes are now available in this Youtube playlist.
*Upcoming*

Also, sign up for the upcoming Community sync happening on 19th November where Amazon Engineering Team will present on their data lake implementation with Apache Hudi.
Community Blogs/Socials
📙Blogs/Videos
I spent 5 hours exploring the story behind Apache Hudi - Vu Trinh

Vu Trinh dives into the origins of Apache Hudi, explaining Uber's motivation to build a framework capable of handling near-real-time ingestion and incremental processing, addressing challenges of high latency and complex data updates. This blog covers Hudi's unique timeline management, data layout, and indexing mechanisms, which set it apart from other table formats like Iceberg and Delta Lake.
Exploring Time Travel Queries in Apache Hudi - Opstree

Opstree's recent article delves into Apache Hudi's time travel feature, enabling users to query historical data versions. The piece offers a hands-on guide to setting up Hudi for time travel queries using AWS Glue and PySpark, demonstrating how to retrieve past data states by specifying commit times.
Streaming DynamoDB Data into a Hudi Table: AWS Glue in Action - Rahul Kumar
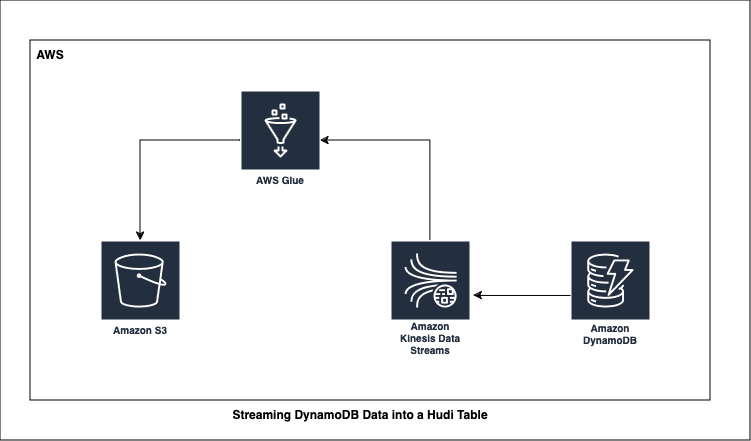
This post by Rahul outlines a real-time data pipeline that captures changes from AWS DynamoDB, processes them with AWS Glue, and stores the results in Apache Hudi tables. The blog provides a step-by-step guide, including setting up Kinesis Data Streams for change data capture, configuring AWS Glue for data transformation, and writing the processed data into Hudi tables. By following this guide, readers can implement a scalable, serverless streaming analytics solution.
Mastering Slowly Changing Dimensions with Apache Hudi & Spark SQL - Sameer Shaik

This blog by Sameer provides practical examples, demonstrating how to implement different SCD types with Hudi and Spark SQL, offering valuable insights for data engineers aiming to optimize their data processing workflows. He explains how Hudi's capabilities facilitate efficient handling of SCDs, which are essential for maintaining historical data accuracy.
Moving Large Tables from Snowflake to S3 Using the COPY INTO Command and Hudi Bootstrapping to Build Data Lakes | Hands-On Labs - Soumil Shah
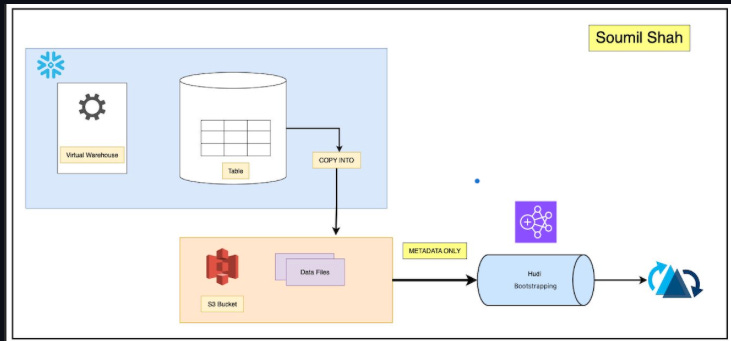
Soumil’s article provides an approach to migrate large tables from Snowflake to an object store like Amazon S3 and how to bootstrap these tables into Apache Hudi to build efficient data lakes. Bootstrapping in Hudi allows you to use existing Parquet files in Hudi format without data duplication. The article includes detailed steps and code.
📱Socials
Apache Hudi on iExec (decentralized compute) for real-time streaming data lake

In this post, Kenneth discusses using Apache Hudi to create an on-chain, decentralized, real-time streaming data lake. This approach integrates blockchain technology with Hudi's capabilities, aiming to enhance data transparency, immutability, and real-time processing in decentralized applications.
Clustering Service deployment in a Hudi Lakehouse
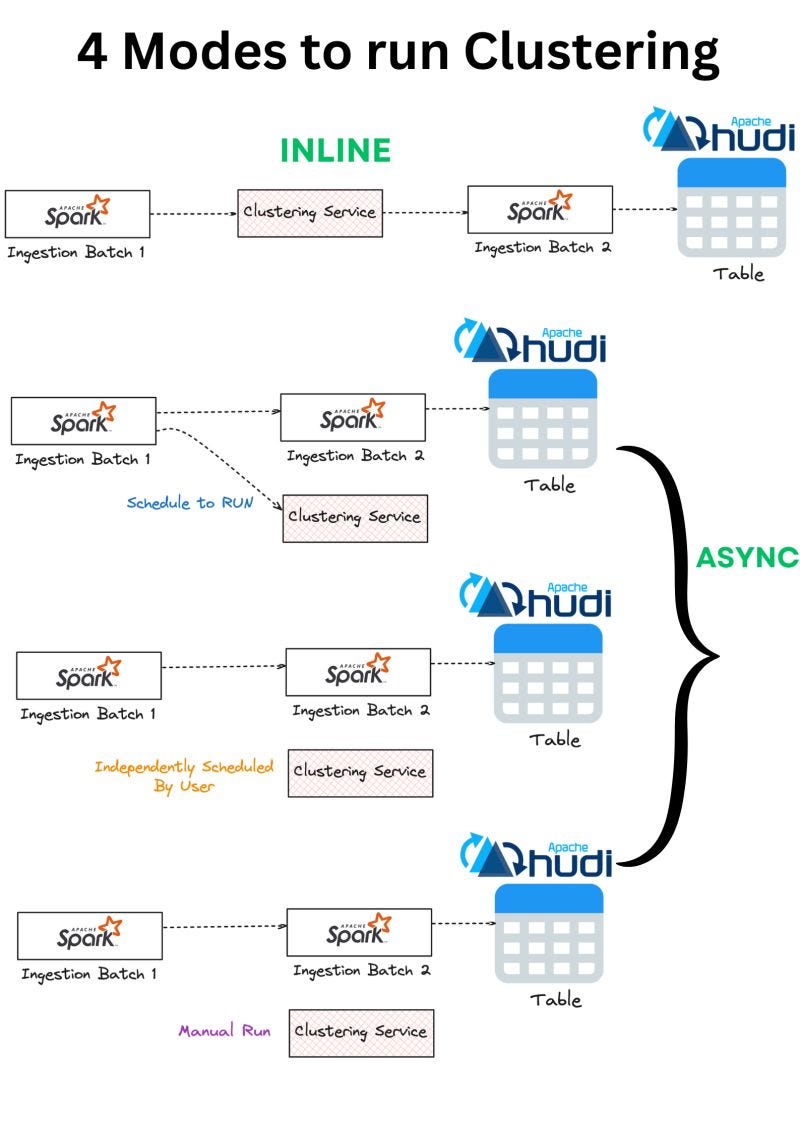
Dipankar’s post explains the various clustering deployment modes available in Apache Hudi. He details how Apache Hudi’s flexible clustering modes (both inline and asynchronous) allow optimizing storage without compromising ingestion speed, balancing performance for varied business needs.
Apache Hudi Primary Key

This post by Sameer highlights the essential role of primary keys in Apache Hudi. Primary keys enable efficient upserts and deletes, support built-in indexing, and ensure key-based deduplication—boosting performance and maintaining data quality, especially in CDC scenarios.
Unlocking Data Efficiency with Apache Hudi

This post emphasizes Apache Hudi’s strengths in data efficiency, enabling near real-time ingestion, incremental processing, and storage optimization. Avinash shares about his experience of offloading millions of rows from databases and streaming sources into S3 as Parquet, then building Hudi tables. With AWS Glue Catalog for metadata management, they achieved significant storage reduction and boosted data processing efficiency.

Also, special thanks 🎉 to Harshdeep Kaur, Software Engineer at Amazon who hosted a session on the best practices and use cases for Apache Hudi. This just shows Hudi’s diverse community members going above and beyond!
Project Updates

GitHub ❤️⭐️ https://github.com/apache/hudi
PR#11788 drops Spark 2 and Scala 11 support
PR#12005 merges RFC-82 that enhances Hudi's concurrency control mechanism to handle concurrent schema evolution scenarios.
PR#11947 is part of an effort of making incremental query use completion timeline by default
hoodie.read.timeline.holes.resolution.policywould no longer have effect onHoodieIncrSource,GcsEventsHoodieIncrSourceandS3EventsHoodieIncrSource.
These sources would always use completion time to find the start instant for incremental query.
PR#12132 enhances the data skipping ability for Apache Flink source by introducing a new partition pruner based on Partition Stats Index.
Hudi Resources
Getting started 🏁
If you are just getting started with Apache Hudi, here are some quick guides to delve into the practical aspects.
Official docs 📗
Join Slack 🤝
Discuss issues, help others & learn from the community. Our Slack channel is a home to 4000+ Hudi users.
Socials 📱
Join our social channels to be in the know about deep technical concepts to tips & tricks and interesting things happening the community.
Twitter/X: https://twitter.com/apachehudi
Weekly Office Hours 💼
Hudi PMC members/committers will hold office hours to help answer questions interactively, on a first-come first-serve basis. This is a great opportunity to bring any doubts.
Interested in Contributing to Hudi?👨🏻💻
Apache Hudi community welcomes contributions from anyone! Here are few ways, you can get involved.
Rest of the Data Ecosystem
If not RocksDB, then what? Why SlateDB is the right choice for Stream Processing - Rohan Desai
Parquet pruning in DataFusion - Xiangpeng Hao
Detect data mutation patterns with Debezium - Fiore Mario Vitale
Improving Parquet Dedupe on Hugging Face Hub - Yuchenglow, Di Xiao
Analytics-Optimized Concurrent Transactions - Mark Raasveldt and Hannes Mühleisen
Have any feedback on documentation, content ideas or the project? Drop us a message!