


Hudi Newsletter#5: July-2024


Hello, Apache Hudi enthusiasts!
We are into the July edition of the Hudi newsletter, brought to you by Onehouse.ai.
To start with, we are super excited to announce the release of ‘Hudi-rs’ - a native Rust library for Apache Hudi with Python bindings.
⭐️ https://github.com/apache/hudi-rs
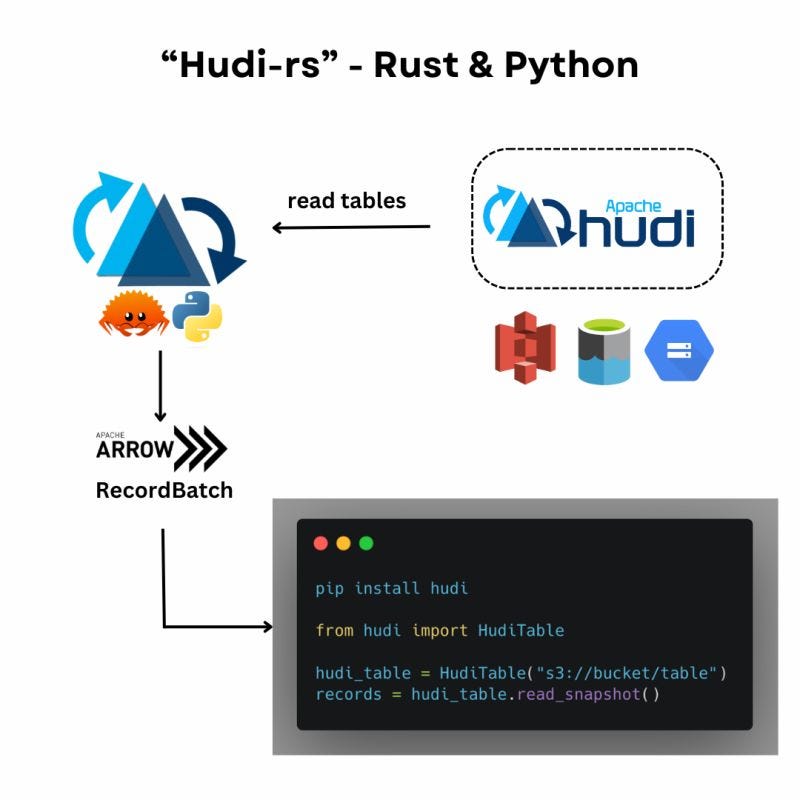
This new project broadens the application of Apache Hudi to a diverse range of use cases within the Rust and Python ecosystems.
Hudi-rs provides the ability to read Hudi tables without having to rely on dependencies such as Apache Spark, Java or Hadoop, making it easier for developers in the Python & Rust ecosystem to access Hudi’s open lakehouse platform.
🏁To get started:
With Python: Install via PyPi:
pip install hudi-rsWith Rust: Add the crate:
cargo add hudi(available on Crates.io)
Community Blogs/Socials
📙Blogs
Building and scaling Notion’s data lake - Notion Data Platform Team

In this blog, Notion details how they built and scaled its in-house data lake using Apache Hudi to cater to their increasing AI and search use cases. Notion faced challenges with ingesting data into their existing warehouse (Snowflake) due to their update-heavy workload, where 90% of upserts were updates rather than new entries. Apache Hudi addressed these challenges by efficiently handling the high volume of updates, ensuring faster and more cost-effective data ingestion. Moreover, moving several large Postgres datasets to an in-house data lake resulted in net savings of over a million dollars with even higher projected savings for 2024.
A Lakehouse by the Kafka Stream - Prabodh Agarwal | Toplyne

Toplyne provides AI solutions to leading SaaS and D2C companies, using advanced data tech to identify and engage high-intent customers. They faced challenges with bulky and costly data ingestion and processing, requiring slow, once-a-day updates and constant performance tuning. To address these issues, Toplyne implemented a lakehouse architecture on Apache Hudi with Apache Kafka as middleware. This custom ingestion layer allows direct streaming of first-party data into their systems, eliminating latency and ETL requirements while reducing vendor lock-in.
What is a Data Lakehouse & How does it work? - Dipankar Mazumdar | Onehouse.ai
This blog explores the concept of a data lakehouse, a hybrid architecture combining the best features of data lakes and data warehouses. It discusses how data lakehouses offer the scalability and low-cost storage of data lakes along with the management and performance features of data warehouses. The article highlights the role of Apache Hudi in enabling this architecture by providing efficient data ingestion, ACID transactions, and incremental processing.
Apache Hudi and Spark - Karl Christian | Careem

Karl Christian goes over how to build a data lakehouse using Apache Hudi and Spark in this hands-on article. The blog provides a step-by-step guide on setting up the environment, ingesting data, and performing incremental processing. Karl highlights the benefits of Hudi for managing large datasets, ensuring data consistency, and optimizing query performance. This practical guide is invaluable for data engineers looking to implement lakehouse architectures.
Implementing Keyword Search in Hudi: Building Inverted Indexes with Record Level Index, Metadata Indexing and Point Lookups | Text search on data lake - Soumil Shah

Soumil Shah presents an exciting new use case for Apache Hudi, demonstrating how to implement keyword search in a data lakehouse by building inverted indexes. The blog provides an in-depth look at the technical steps involved in setting up inverted indexes with Hudi, explaining how this enhances search efficiency and performance. It highlights the benefits of Hudi’s indexing capabilities for scalable and efficient data retrieval, enabling powerful search capabilities in a big data environment.
📱Socials
Understanding Apache Hudi: Key Features and Concepts
Ankita provides an overview of Apache Hudi's key features and concepts. The post highlights Hudi's support for ACID properties, efficient upserts, data versioning, and rollbacks, which are essential for robust production operations. It also covers core concepts like primary keys, partition fields, and pre-combine keys, along with the advantages of incremental queries and the Hudi commit timeline.
Credit Risk using Jarrow-Turnbull Model for Bond Market
Harshavardhan shares an innovative project for credit risk modeling for the bond market. The project uses Apache Spark and Apache Hudi to build a scalable data processing pipeline for bond price simulation and risk assessment. Key components include data ingestion, storage in Apache Hudi for efficient handling and versioning, data transformation with Apache Spark, and visualization using Matplotlib.
LSM Tree Style Timeline - Apache Hudi 1.0
Apache Hudi 1.0 introduces the LSM (log-structured merge) tree style timeline, enhancing the core timeline functionality crucial for ACID transactions, querying the latest data, incremental processing, and time-travel. In this post, Dipankar explains how this new design allows the timeline to handle an increasing number of commits without adding read latency, enabling infinite time travel and non-blocking concurrency control.
Using OpenAI Vector Embeddings with Apache Hudi
In this post, Soumil explains how to efficiently store and manage large OpenAI vector embeddings using Apache Hudi. The post delves into the technical setup and benefits of integrating Hudi with OpenAI’s vector embeddings for scalable and efficient data storage.
ByteDance’s Data Lake with Apache Hudi
ByteDance has built a state-of-the-art data lake using Apache Hudi, capable of managing exabyte-scale datasets. In this post, Shashank highlights Hudi's key innovations and capabilities, including efficient data ingestion and upserts, incremental processing, and optimized storage and query performance, which have enabled ByteDance to construct a real-time data lake architecture.
More from the Community
The Data Guy has a great introductory video about Apache Hudi. Check it out!
Project Updates

GitHub ❤️⭐️ https://github.com/apache/hudi
PR #11529 is an improvement to the HiveSyncTool that allows it to recreate tables when the base path doesn't match the glue/hive table location.
PR #11471 brings a new sql command `SHOW CREATE TABLE ` now allows to print ‘create table’ statements.
PR #11570 adds an end-to-end example to showcase Hudi, Flink and MinIO integration.
With PR #11604, we can now compile Hudi with Java 17.
PR #11490 enables support for incremental CDC query with Apache Flink for Merge-on-Read (MoR) tables.
Ecosystem Updates
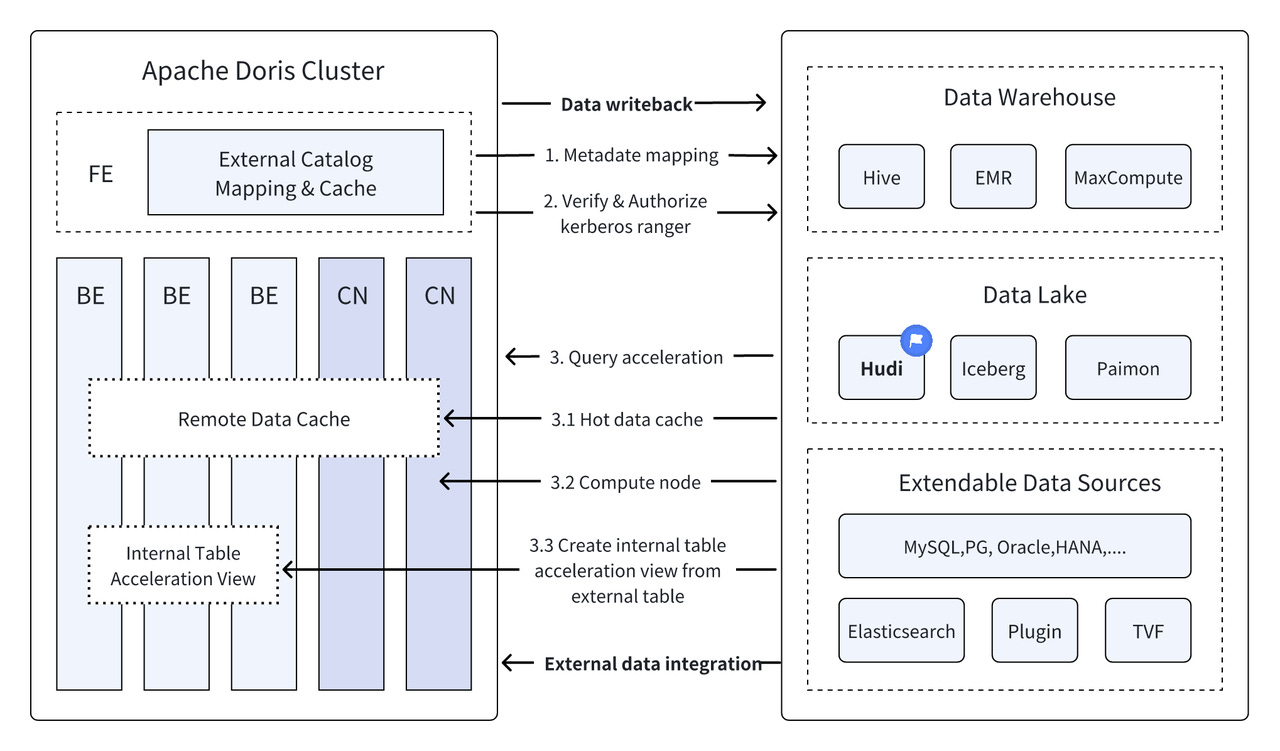
On the Query engine-side, the Apache Doris team has just released an exciting "Apache Doris & Hudi Quick Start" guide, designed to help you quickly set up a test and demo environment using Docker. Apache Doris is an MPP-based real-time data warehouse known for its high query speed. This comprehensive guide will walk you through deploying the powerful combination of Doris and Hudi, showcasing their key features.
Community Events
🎭 Past Events

In the July month community sync, Subash from Metica Engineering presented their data platform journey with Apache Hudi. The talk highlighted Hudi’s crucial role from the initial bootstrap phase to the development of advanced features. Subash shared insights into why Hudi became their top choice for an open table format after evaluating other options a year ago. He also discussed how various table services in Hudi have minimized maintenance overhead and simplified usage through smart configurations.

Ethan Guo, Hudi PMC, presented on enhancing query performance in PrestoDB and Trino using Apache Hudi at PrestoConDay and Trino Fest 2024. They showcased the development of the Hudi connector in both engines, highlighting specialized features like the multi-modal indexing framework with support for Column Statistics and Record Index.

And, Kyle Weller demoed how to sync Apache Hudi tables to the recently released Unity Catalog using Apache XTable (incubating) at the Unity Catalog Meetup.
Hudi Resources
Getting started 🏁
If you are just getting started with Apache Hudi, here are some quick guides to delve into the practical aspects.
Official docs 📗
Join Slack 🤝
Discuss issues, help others & learn from the community. Our Slack channel is a home to 4000+ Hudi users.
Socials 📱
Join our social channels to be in the know about deep technical concepts to tips & tricks and interesting things happening the community.
Twitter/X: https://twitter.com/apachehudi
Weekly Office Hours 💼
Hudi PMC members/committers will hold office hours to help answer questions interactively, on a first-come first-serve basis. This is a great opportunity to bring any doubts.
Interested in Contributing to Hudi?👨🏻💻
Apache Hudi community welcomes contributions from anyone! Here are few ways, you can get involved.
Rest of the Data Ecosystem
Run Apache XTable on Amazon MWAA to translate open table formats - Matthias Rudolph & Stephen Said (AWS)
Differential Backups in MyRocks Based Distributed Databases at Uber - Uber Engineering
Memory Management in DuckDB - Mark Raasveldt
Do we fear the serializable isolation level more than we fear subtle bugs - Evgeniy Ivanov
[Research Paper] BOSS - An Architecture for Database Kernel Composition
Have any feedback on documentation, content ideas or the project? Drop us a message!