


Hudi Newsletter#4: June-2024


Hello, Apache Hudi enthusiasts!
Welcome to the June edition of the Hudi newsletter, brought to you by Onehouse.ai.
This month has been packed with exciting developments and updates!
First and foremost, we have fantastic news 🎉: Onehouse has successfully raised $35M in a Series B funding round! This milestone fuels our passion and commitment to growing and enhancing the Hudi community even further.
With this thrilling news, we’re also thrilled to announce two new product releases from Onehouse for Apache Hudi. Here’s a quick overview.
Be sure to check them out!
LakeView
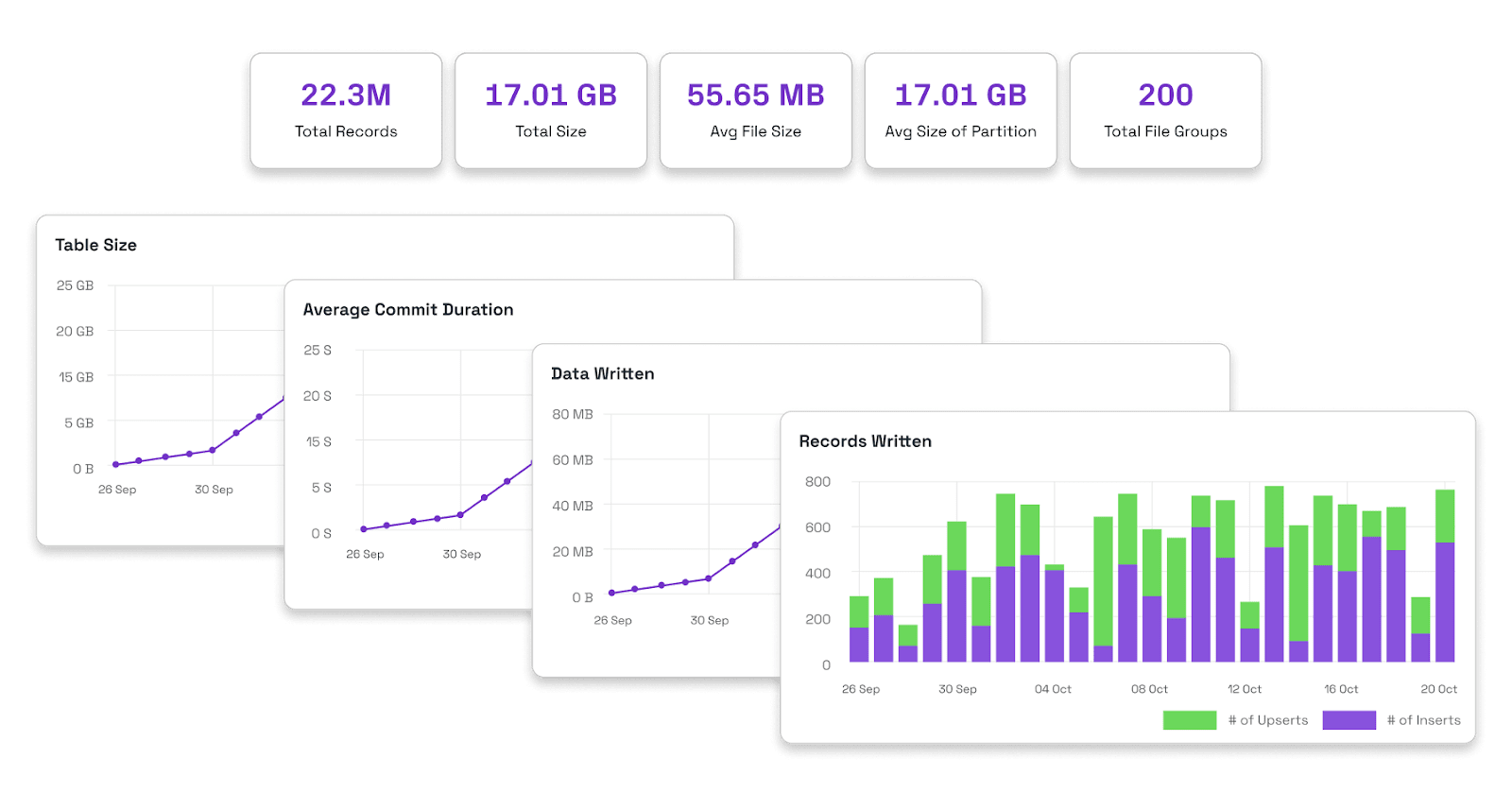
LakeView is a free solution that enhances data lakehouse observability by providing a user interface with metrics, charts, and insights. It helps monitor Apache Hudi tables, optimize performance, and debug data issues. Key features include a bird's-eye view of all the tables, weekly email summaries, performance optimization opportunities, and proactive monitoring with configurable alerts.
Table Optimizer
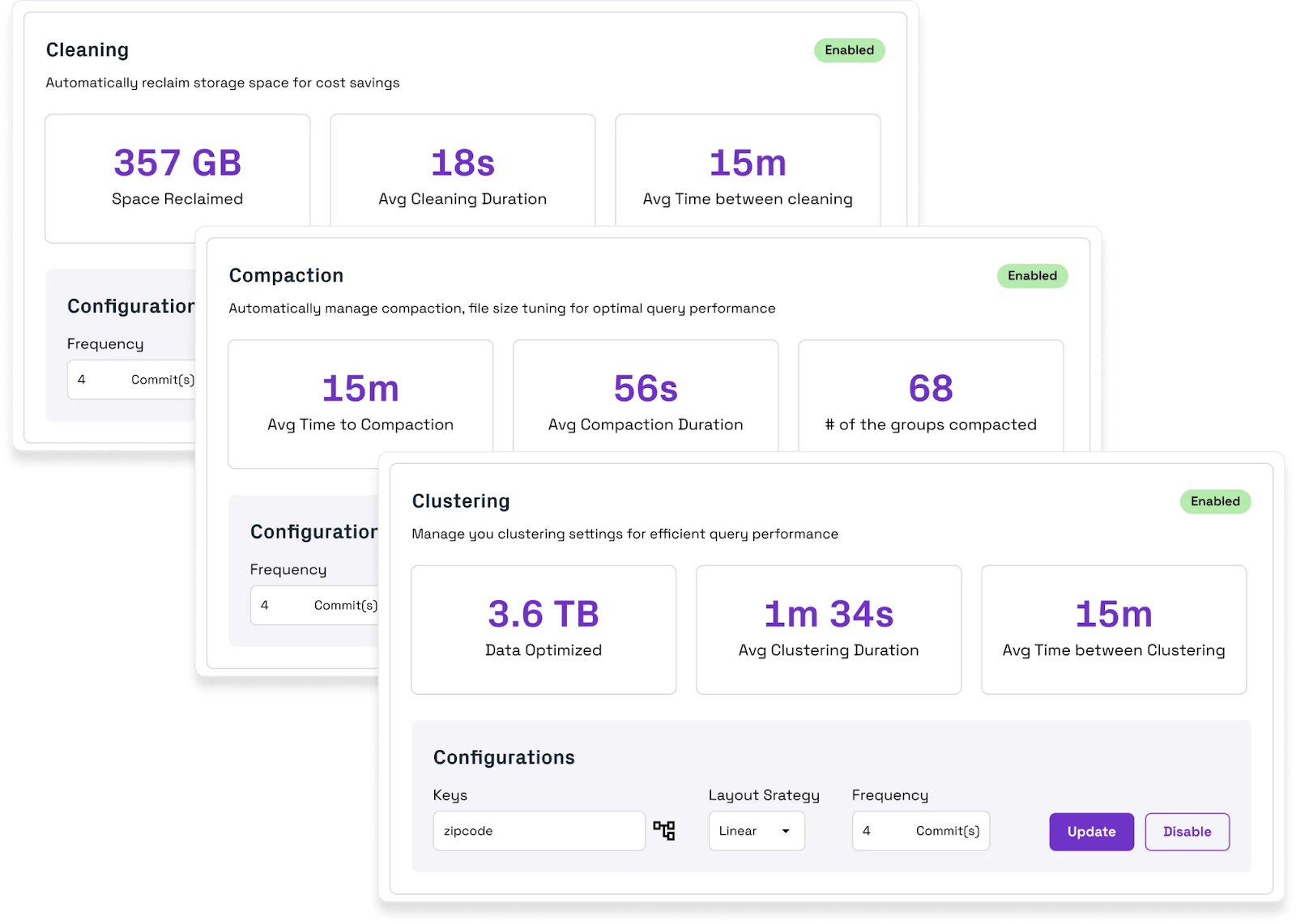
Table Optimizer is another offering designed to automatically optimize lakehouse table layouts, improving query performance and reducing operational costs whether you are using the Onehouse platform or self-managed Apache Hudi, Apache Iceberg, or Delta Lake. It offers key features such as auto file-sizing, intelligent incremental clustering, adaptive compaction, automatic cleaning, and asynchronous services. These features streamline data management, enhance performance, and integrate seamlessly with existing pipelines without requiring migration.
Project Updates
GitHub ❤️⭐️ https://github.com/apache/hudi
We are super excited to see Apache Hudi 0.15.0 being released this month.

This release introduces a bunch of new things and improvements to existing ones, including:
✅ New Storage & I/O Abstractions: Hudi now introduces Hadoop-agnostic storage and I/O abstractions, enhancing integration with query engines like Trino. This includes new classes such as HoodieStorage and HoodieIOFactory for better flexibility and Hadoop-independent implementations.
✅ Extended Engine Support:
Spark 3.5 & Scala 2.13: Support for Spark 3.5 and Scala 2.13, ensuring compatibility with previous versions down to Spark 2.4.
Flink 1.18: Added support with new bundles to facilitate integration, streamlining Hudi’s use with Flink’s latest version.
✅ Meta Sync Improvements:
Glue Catalog Sync: Enhanced with parallel listing capabilities for partitions, significantly reducing meta sync latency.
BigQuery Sync: Optimized through metadata table usage, improving file listing performance by loading all partitions once.
Check out the detailed release notes for all the updates.
Community Blogs/Socials
📙Blogs
Apache Hudi - The Open Data Lakehouse Platform We Need - Vinoth Chandar

In this blog, Apache Hudi creator and PMC Chair Vinoth Chandar examines Hudi through the lenses of Community, Competition, and Cloud Vendors. He highlights Hudi's strong, innovative community and its crucial role in supporting major data lakes and cloud vendors. The blog emphasizes Hudi’s position as an open data lakehouse platform, not just a table format, and underscores the importance of open compute services for a no-lock-in architecture. It also discusses Hudi’s efficiency in handling incremental workloads and its history of pioneering data lakehouse innovations. The article advocates for informed decision-making based on technical merits and hints at future advancements in open-source data lake databases.
Apache Hudi: A Deep Dive with Python Code Examples - Harsh Daiya

In this blog, Harsh Daiya offers a technical deep dive into Apache Hudi, featuring PySpark code examples. Using a business scenario for clarity, the blog explores Hudi’s architecture, key features, and practical implementations. Readers will gain insights into setting up Hudi, ingesting data, and querying it, making this an essential guide for both new and experienced users.
How Jobtarget Utilized Apache Hudi's Time Travel Query to Investigate Bid and Spend | Going Back in Time with Hudi - Soumil Shah

Soumil details how JobTarget leverages Apache Hudi's time travel query feature to track bids and spend values over time in this piece. The blog explores the implementation process and benefits of using time travel queries for efficiently querying historical data and ensuring data consistency. It provides a solid example of how Hudi’s capabilities can be applied to tackle complex real-world problems.
How to use Apache Hudi with Databricks - Sagar Lakshmipathy
Looking to use Apache Hudi with Databricks? This blog offers a step-by-step guide to setting up Apache Hudi on Databricks, including configuration tips and best practices for optimal performance. It highlights the benefits of using Hudi with Databricks, showcasing Hudi’s unique capabilities such as incremental processing, a multi-modal indexing subsystem, and advanced merge-on-read configurations.
📱Socials
Nishant goes over a scenario-based use case and practical example of how one can use Apache Hudi to analyze real-time customer transactions for an e-commerce company. Hudi enables the ingestion and storage of real-time data, supports real-time updates, and allows for incremental processing to generate analytics and reports.
In this video guide with code examples, Soumil shows how easy and quickly you can get started with creating Apache Hudi tables using AWS Glue notebook and run various read and write operations.
Dipankar explains how Apache Hudi's incremental processing enhances efficiency, data freshness, and cost-effectiveness by processing only data changes, using Uber's 'Trips' database as an example in this post. The post goes over how this approach reduces computational load and improves real-time data availability compared to traditional bulk uploads.
In this exploratory post, Gatsby Lee tests out the patched version of Apache Hudi 0.14.1 by Amazon EMR in 7.1.0 and presents how it provides faster performance with Spark 3.5. Note that the official Hudi 0.14.1 doesn't support Spark 3.5; to use Spark 3.5, Hudi 0.15.0 is recommended.
Community Events
Past Events

June was a bustling month for conferences! Apache Hudi contributors, committers, and PMC members showcased Hudi’s advantages and related open-source projects, such as Apache XTable, at major events including the Snowflake Summit, Databricks’ Data+AI, Trino Fest, and PrestoCon Day. These presentations highlighted Hudi’s innovative solutions and its growing impact in the data community.
It was also amazing to have Ali Ghodsi, CEO of Databricks visit Onehouse’s booth to see some demo in action at the Data+AI Summit.
Hudi Resources

Getting started 🏁
If you are just getting started with Apache Hudi, here are some quick guides to delve into the practical aspects.
Official docs 📗
Join Slack 🤝
Discuss issues, help others & learn from the community. Our Slack channel is a home to 4000+ Hudi users.
Socials 📱
Join our social channels to be in the know about deep technical concepts to tips & tricks and interesting things happening the community.
Twitter/X: https://twitter.com/apachehudi
Weekly Office Hours 💼
Hudi PMC members/committers will hold office hours to help answer questions interactively, on a first-come first-serve basis. This is a great opportunity to bring any doubts.
Interested in Contributing to Hudi?👨🏻💻
Apache Hudi community welcomes contributions from anyone! Here are few ways, you can get involved.
Rest of the Data Ecosystem
Diving into the Presto Native C++ Query Engine - Aditi Pandit (IBM), Amit Dutta (Meta)
A Cost Analysis Of Replication Vs S3 Express One Zone In Transactional Data Systems - Jack Vanlightly (Confluent)
Columnar File Readers in Depth: APIs and Fusion - Weston Pace (LanceDB)
How Uber ensures Apache Cassandra®’s tolerance for single-zone failure - Uber Engineering
Understanding Compression Codecs in Apache Parquet - Dipankar Mazumdar (Onehouse.ai)
[Research Paper] What Goes Around Comes Around... And Around...
Have any feedback on documentation, content ideas or the project? Drop us a message!
Great community recap