


Hudi Newsletter#3: May-2024


Hello, Apache Hudi enthusiasts!
Welcome to the May edition of the Hudi newsletter, presented by Onehouse.ai.
Before we dive into all the exciting updates, check out this awesome new ebook that provides an end-to-end learning guide for everything Apache Hudi. And it’s FREE!
👉Link to download: https://www.onehouse.ai/resources/ebook-apache-hudi-zero-to-one

Community Blogs/Socials
📙Blogs
Use AWS Data Exchange to seamlessly share Apache Hudi datasets - Amazon Web Services, Onehouse
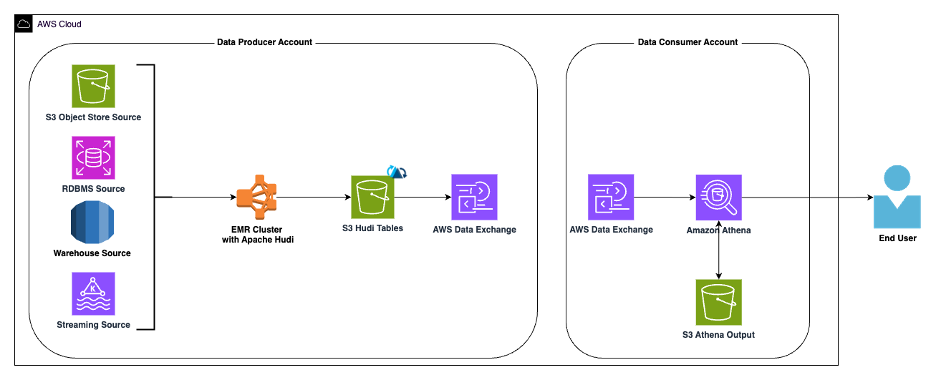
AWS Data Exchange enables you to find, subscribe to, and use third-party datasets in AWS Cloud. This blog demonstrates how to use AWS Data Exchange on top of Apache Hudi tables in a S3 data lake to take advantage of its secure, reliable, and user-friendly data sharing capabilities. It outlines the seamless integration process and highlights the efficiency gains and collaborative benefits for users working with Apache Hudi datasets, emphasizing secure data access and accelerated analytical insights.
Building Analytical Apps on the Lakehouse using Apache Hudi, Daft & Streamlit - Dipankar Mazumdar
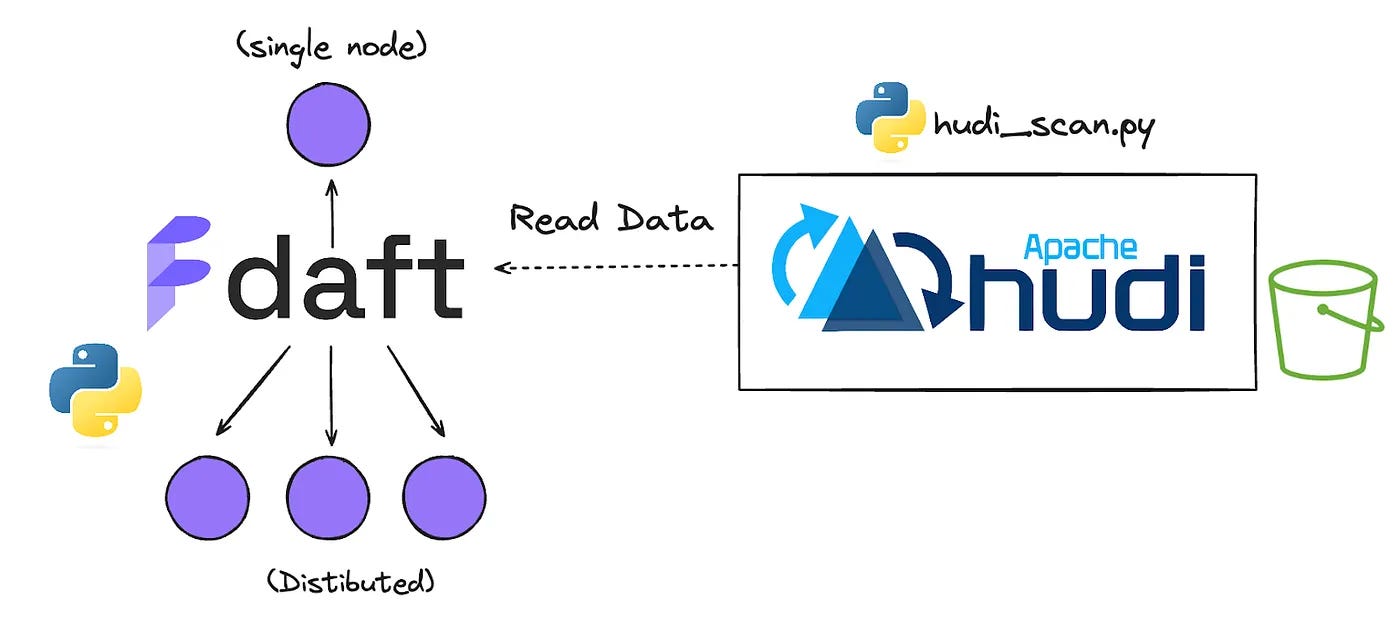
Lakehouse workloads are predominantly distributed in nature to effectively handle large volumes and varieties of data. On the compute engine side, Spark is one of the most common choices for batch-style processing, which involves setting up clusters and JVM processes. However, not every use case requires distributed processing. Specifically, the demand for using data directly from a lakehouse platform to build single node analytical applications on top is on the rise. This blog provides a hands-on experience of building a purely Python-based dashboard on top of Apache Hudi by leveraging Daft—a distributed query engine with familiar Python APIs.
Apache Hudi on AWS Glue - Sagar Lakshmipathy

Curious about writing Hudi tables in AWS Glue? This hands-on blog goes straight into using AWS Glue ETL jobs to seamlessly write Apache Hudi tables within S3 data lakes, offering practical insights and step-by-step guidance for efficient data management.
Incremental ETL from Hudi Tables Using DeltaStreamer and Using Broadcast Joins for Faster data Processing - Soumil Shah
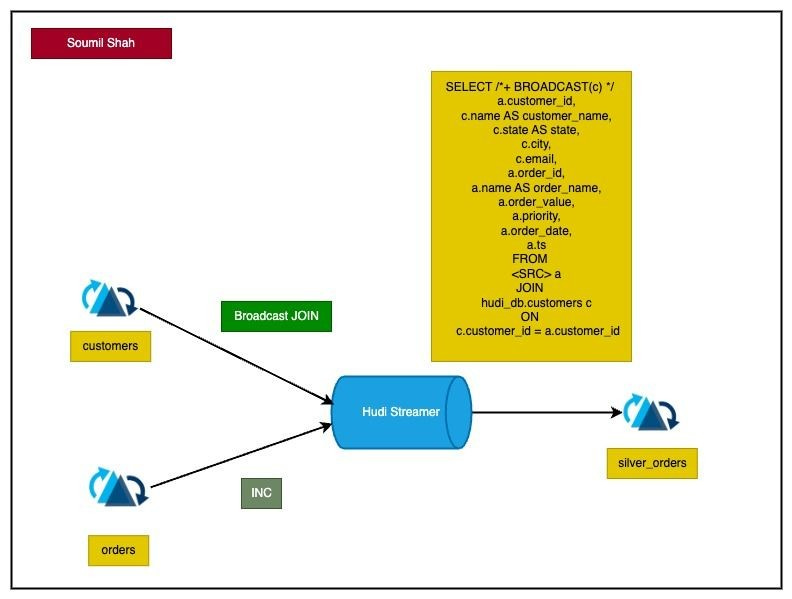
In this blog post, Soumil goes over implementing incremental ETL from Apache Hudi tables using Apache Spark’s broadcast joins which are particularly beneficial for large datasets and incremental ETL. The blog shows how by using Hudi tables and broadcast joins, you can streamline your data processing for enhanced scalability and performance.
Optimizing JobTarget’s Data Lake: Migrating to Hudi, a Serverless Architecture, and Templated Glue Jobs
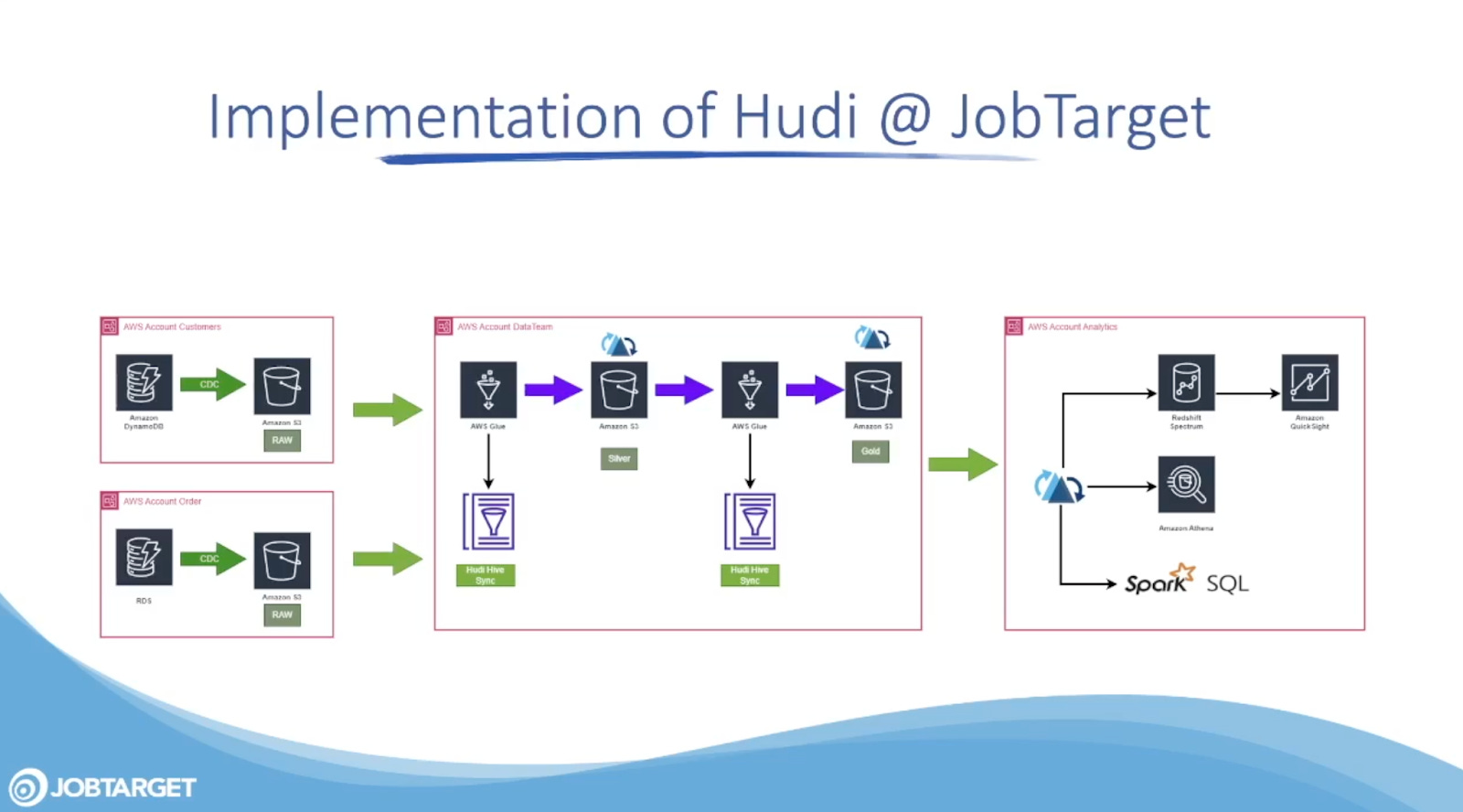
This blog presents JobTarget's (an online job search platform) data lake migration journey to Apache Hudi within a serverless architecture and utilizing templated Glue jobs. Experiencing a quick rise in data volume, with storage doubling within a short timeframe, JobTarget recognized the necessity for a scalable solution. The blog reveals insights into the decision-making process and the aggressive optimization tactics employed in this journey. Central to their strategy is the implementation of LakeBoost, an AWS Glue-based ingestion framework, now available as an open-source project, amplifying the efficiency and scalability of their Hudi data lake.
📱Socials
Real-Time Data Ingestion with Apache Hudi on Microsoft Azure
In this post, Shashank discusses a real-time data ingestion pipeline using Apache Hudi on Microsoft Azure. The post highlights the key benefits of Hudi, including its support for various table types such as Copy on Write and Merge on Read, improved data freshness through faster upserts, and capabilities like time travel for historical querying.
File Formats for Streaming Ingestion & Apache Hudi’s design decisions
Highlighting the limitations of Parquet for streaming ingestion, this post by Jorrit presents Avro as a better alternative due to its row-oriented structure. The post also goes over how Apache Hudi intelligently combines Avro's fast writes with Parquet's efficient storage, enabling dynamic updates for real-time querying, presenting a compelling solution for high-volume event-based data ingestion.
Hudi Streamer Implementing Slowly Changing Dimension and Query with Trino
This video provides a comprehensive, hands-on guide on how to use Apache Hudi's HudiStreamer to build a SCD-2 dimension. Soumil deep dives into writing custom SQL transformations, syncing Hudi data to the Hive metastore, and how to run real-time queries on the data using Trino as the query engine.
Storage Engine in Databases & their role in Lakehouse architecture
Backbone of Data Systems: The Storage Engine. Often less talked about but important, it's the storage engine that shapes how data is stored, retrieved, and managed in databases, be it OLTP or OLAP. The post also goes over how storage engines are critical in Lakehouse architectures such as Apache Hudi that brings those transactional database capabilities. Dive into this insightful read!
Project Updates

GitHub ❤️⭐️ https://github.com/apache/hudi
PR #10900 introduces a new configuration option, HOODIE_SPARK_DATASOURCE_OPTIONS designed for use by the Spark DataFrame reader for HoodieIncrSource. It allows for the passing of various options, such as enabling the metadata table and data skipping for efficient pruning of files.
PR #11070 adds support for deserializing with Confluent's proto deserializer and includes a new converter to transform responses from SchemaRegistryProvider to Avro for Proto topics. This update provides easier integration for users employing Confluent + Proto with the Hudi Streamer.
PR #11156 introduces partition TTL (time-to-live) for Apache Flink, offering enhanced flexibility in claiming storage space.
PR #11130 adds support for Scala 2.13 in its integration with Spark 3.5, facilitating the building of Spark-related modules and ensuring compatibility with Scala's updated collection conversions.
In a major update, PR #11124 enables the metadata table by default for Apache Flink, streamlining its integration and ensuring smoother operation with the asynchronous table service.
PR #10191 enhances Spark's ability to utilize the bucket field as a filter in table queries. By supporting expressions like equals, in, and, or, it improves query performance for tables with Hudi bucket index.
PR #11216 addresses the issue where the hoodie.datasource.write.row.writer.enable setting was true by default, ignoring the hoodie.combine.before.insert setting even if explicitly set by users. This update changes the behavior to disable row writing for BULK_INSERT operations without meta fields when COMBINE_BEFORE_INSERT is enabled.
Community Events
Past Events

The May month was filled with some amazing community events around Apache Hudi. Sagar Sumit and Vinish presented about seamless streaming ingestion with Apache Hudi and Kafka at the Bengaluru Streams meetup held at Rakuten. Their presentation showcased real-time data processing capabilities by using these technologies.
Meanwhile, Apache Hudi hosted its inaugural community meetup in Bangalore, India, in collaboration with Navi. The sessions provided attendees with deep insights into Apache Hudi 1.0, exploring its database experience on data lakes. Other topics included real-time analytics use cases with Hudi at Navi, as well as Upstox's utilization of Hudi's incremental query and time-travel capabilities for cost savings and historical analysis.
And that’s not all! The Apache Hudi May month community sync had a great presentation by Amarjeet Singh, Senior Data Engineer at Zupee - an online gaming company in India. They discussed how Apache Hudi & HudiStreamer is utilized in Zupee’s data platform to optimize the cost of data lake while enabling real-time ingestion.
Upcoming Events (in June)
Trino Fest 2024 - Enhancing Trino’s query performance and data management with Apache Hudi
Trino Fest is coming to Boston this year on June 13th and we will have Ethan Guo, Apache Hudi PMC and Data Infrastructure Engineer at Onehouse speak about he ambitious roadmap for the Hudi connector, including the expansion of the multi-modal indexing framework, Alluxio-powered file system caching, and the introduction of DDL/DML support. These advancements promise to further refine data management capabilities with the Hudi connector in Trino, offering more flexibility and efficiency in handling large-scale data operations. Register here.
PrestoCon Day 2024 - Presto-Hudi Connector: Innovations & Future

Ethan will also be speaking at PrestoCon Day happening virtually on June 25th 2024. This session will go over the evolution of Presto Hudi connector and its distinctive features that distinguish it from traditional file listing and partition pruning approaches for query optimization in systems like Presto. Register for free here.
Hudi Resources
Getting started 🏁
If you are just getting started with Apache Hudi, here are some quick guides to delve into the practical aspects.
Official docs 📗
Join Slack 🤝
Discuss issues, help others & learn from the community. Our Slack channel is a home to 4000+ Hudi users.
Socials 📱
Join our social channels to be in the know about deep technical concepts to tips & tricks and interesting things happening the community.
Twitter/X: https://twitter.com/apachehudi
Weekly Office Hours 💼
Hudi PMC members/committers will hold office hours to help answer questions interactively, on a first-come first-serve basis. This is a great opportunity to bring any doubts.
Interested in Contributing to Hudi?👨🏻💻
Apache Hudi community welcomes contributions from anyone! Here are few ways, you can get involved.
Rest of the Data Ecosystem
Using Parquet’s Bloom Filters - Trevor Hilton
Optimizing storage costs and query performance by compacting small objects - AWS
Navigating the Streamverse: A Technical Odyssey into Advanced Stream Processing at Dream11 - Dream11 Engineering
Using XTable to translate from Iceberg to Hudi & Delta Lake with a File System Catalog like S3 - Dipankar Mazumdar
[Research Paper] Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database
Have any feedback on documentation, content ideas or the project? Drop us a message!