


Hudi Newsletter#2: April-2024


Hello, Apache Hudi enthusiasts!
We are in the 2nd edition of our monthly Hudi newsletter, your go-to source for everything Apache Hudi. This new newsletter is brought to you by Onehouse.ai with the aim of bringing the vibrant Hudi community even closer together.
Let’s go!
Hudi in the Ecosystem
Daft + Apache Hudi Integration - Eventual | Daft

Daft is a fast and distributed Query Engine with a familiar Python API. It caters to a range of use cases such as multi modal data processing, batch data processing, EDA & data ingestion for training Machine Learning models. With this integration, Apache Hudi users can now read Hudi Copy-on-Write (CoW) tables directly from object stores such as S3 to run Python-based workloads without the need for JVM or Spark. We can’t wait to see what Hudi users build with this new possibility. There is also work in progress to include support for incremental reads, Merge-on-Read (MoR) read, Hudi 1.0 support and writing data to Hudi tables.
Support for Apache Hudi was added to Delta Universal Format - Databricks | Delta Lake
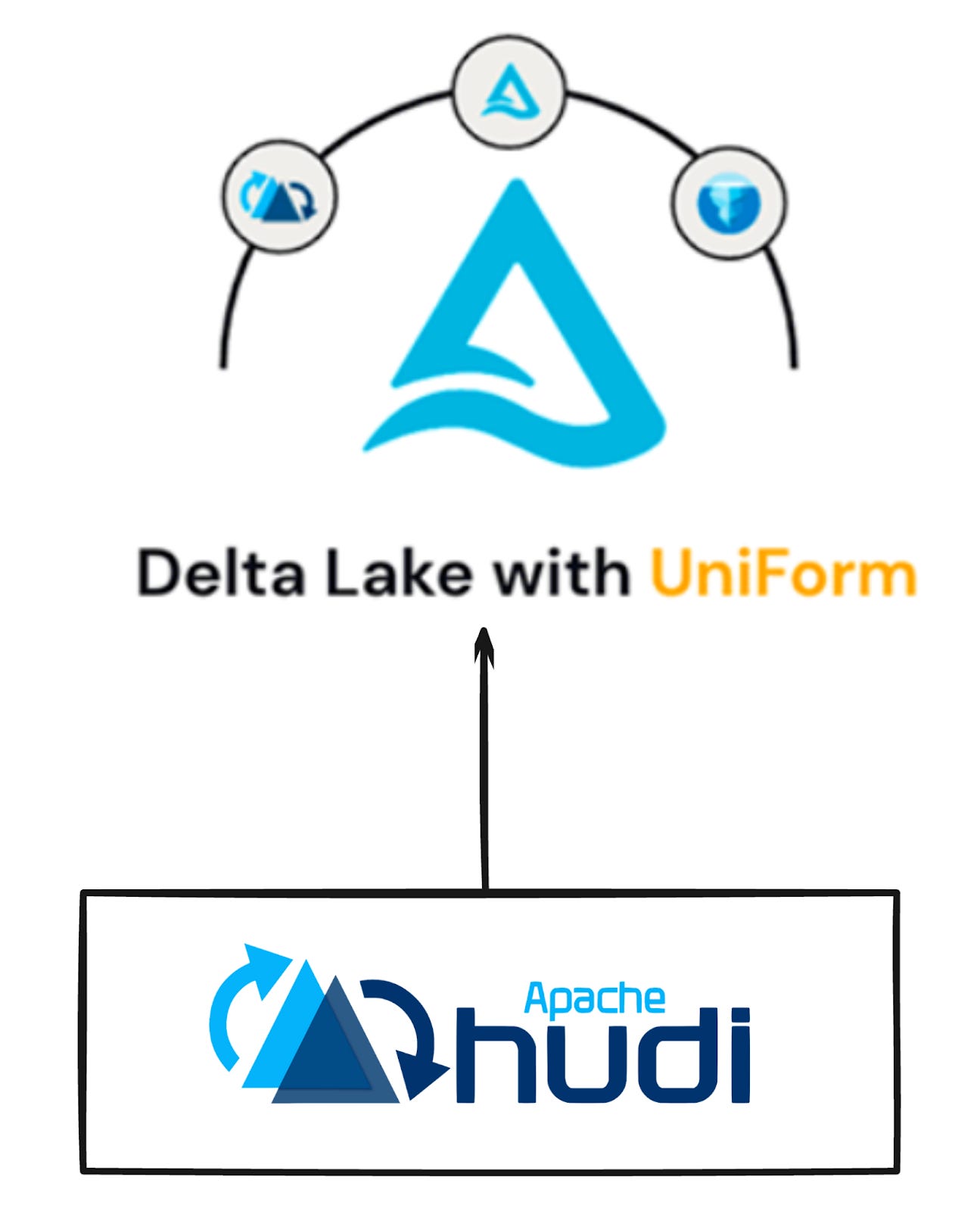
This integration introduces support for Apache Hudi within the Delta Universal format. Now you can write to a Delta Universal table to generate Hudi metadata alongside Delta metadata. The feature is enabled by Apache XTable (incubating). With this command, a UniForm-enabled table named "T" is created, and Hudi metadata is automatically generated alongside Delta metadata when writing to this table.
CREATE TABLE T (c1 INT) USING DELTA TBLPROPERTIES ('delta.universalFormat.enabledFormats' = hudi);
Community Blogs/Socials
📙Blogs
Understanding Apache Hudi’s Consistency Model (3 part series) - Jack Vanlightly | Confluent
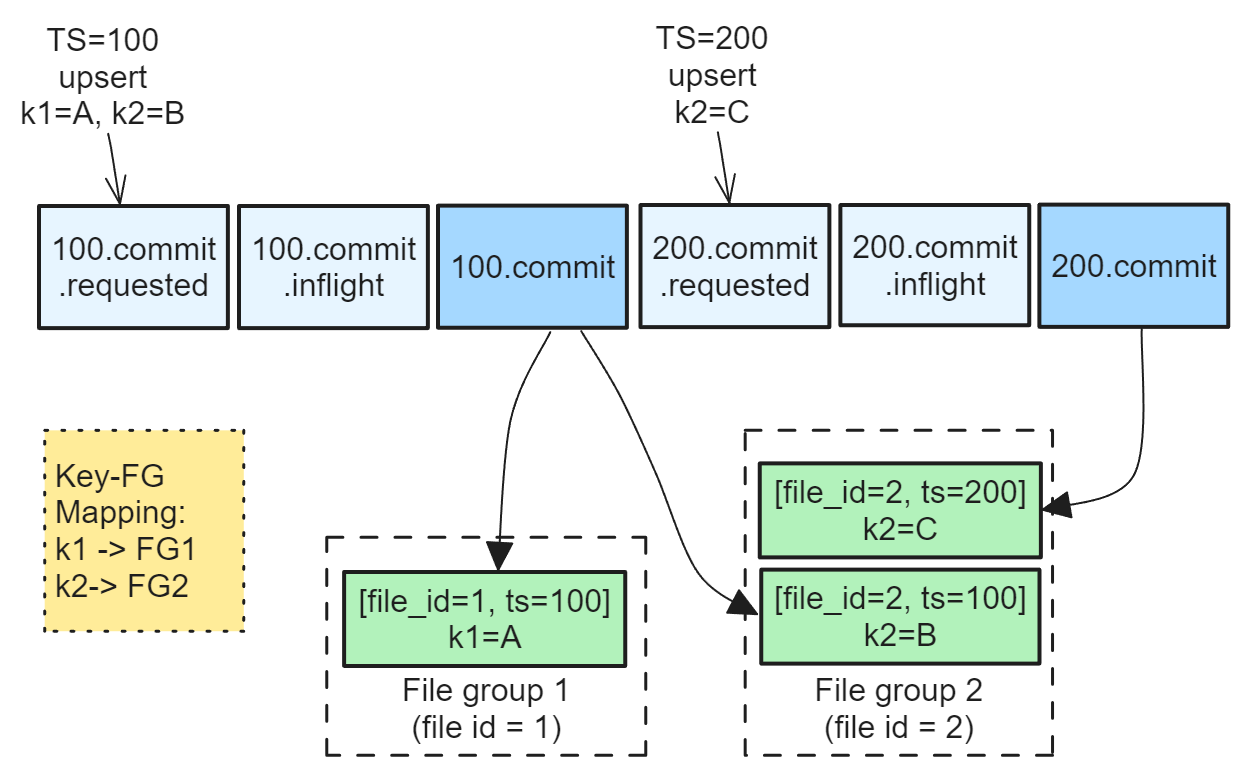
This comprehensive three-part series offers an in-depth exploration of Apache Hudi's consistency model, specifically focusing on handling multiple concurrent writers for the Copy-on-Write (CoW) table type. This series is essential for anyone interested in delving into the intricacies of Hudi. In Part 1, Jack constructs a logical framework for understanding CoW tables. Part 2 delves into the principles of timestamp monotonicity and the final instalment examines the outcomes of model verification using the TLA+ specification.
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-on - Md Shahid Afridi P
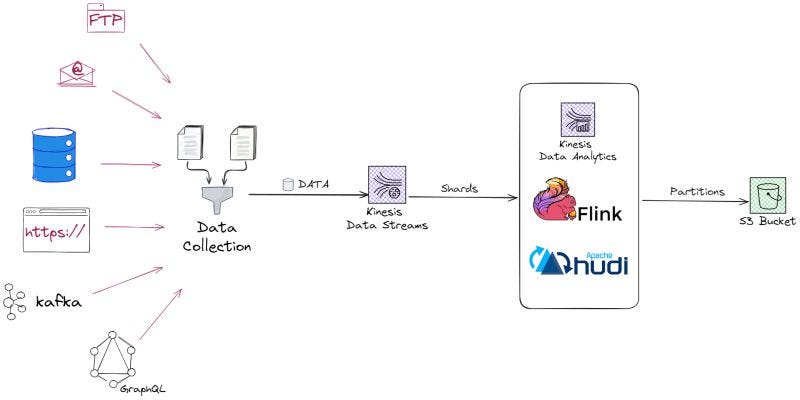
In this blog, Shahid details how to build a real-time streaming pipeline using Apache Hudi, Kinesis, Flink, and S3. The tutorial provides a step-by-step guide on building a real-time streaming pipeline starting from data ingestion using Amazon Kinesis to processing with Apache Flink, and managing storage using Hudi on S3 with practical code implementations and setup configs.
DaaS: Building a Low-Cost Lakehouse for Near Real-Time Analytics in Flink and Hudi - Diogo Santos | Talkdesk
Diogo’s blog presents a detailed guide for building a cost-effective lakehouse architecture using Apache Flink and Hudi for near real-time analytics. It outlines the integration of Flink and Hudi to streamline processes like incremental data updates, efficient upserts, and data compaction. The article includes a comprehensive step-by-step setup from initial data ingestion with Kafka to metadata management with Hive and stream processing with Flink, demonstrating how to achieve efficient and scalable data handling at a reduced cost.
Reading Data from Hudi Tables Incrementally, Joining with Delta Tables using HudiStreamer and SQL-Based Transformer - Soumil Shah | Jobtarget
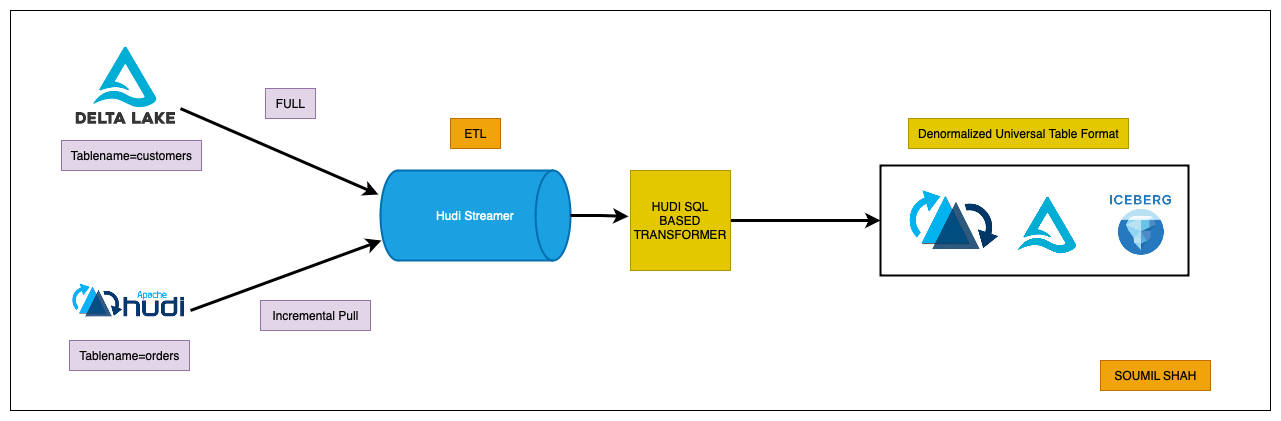
Soumil provides a practical guide on using Apache Hudi, Delta Lake, and HudiStreamer to build denormalized tables within a data lake architecture. They explain how to set up a Dockerized environment to create Hudi and Delta tables, and utilize HudiStreamer along with a SQL-based transformer to enhance data analytics and reporting capabilities.
Apache Hudi: Load Hudi Cleaner’s AVRO content - Gatsby Lee | Forethought.ai
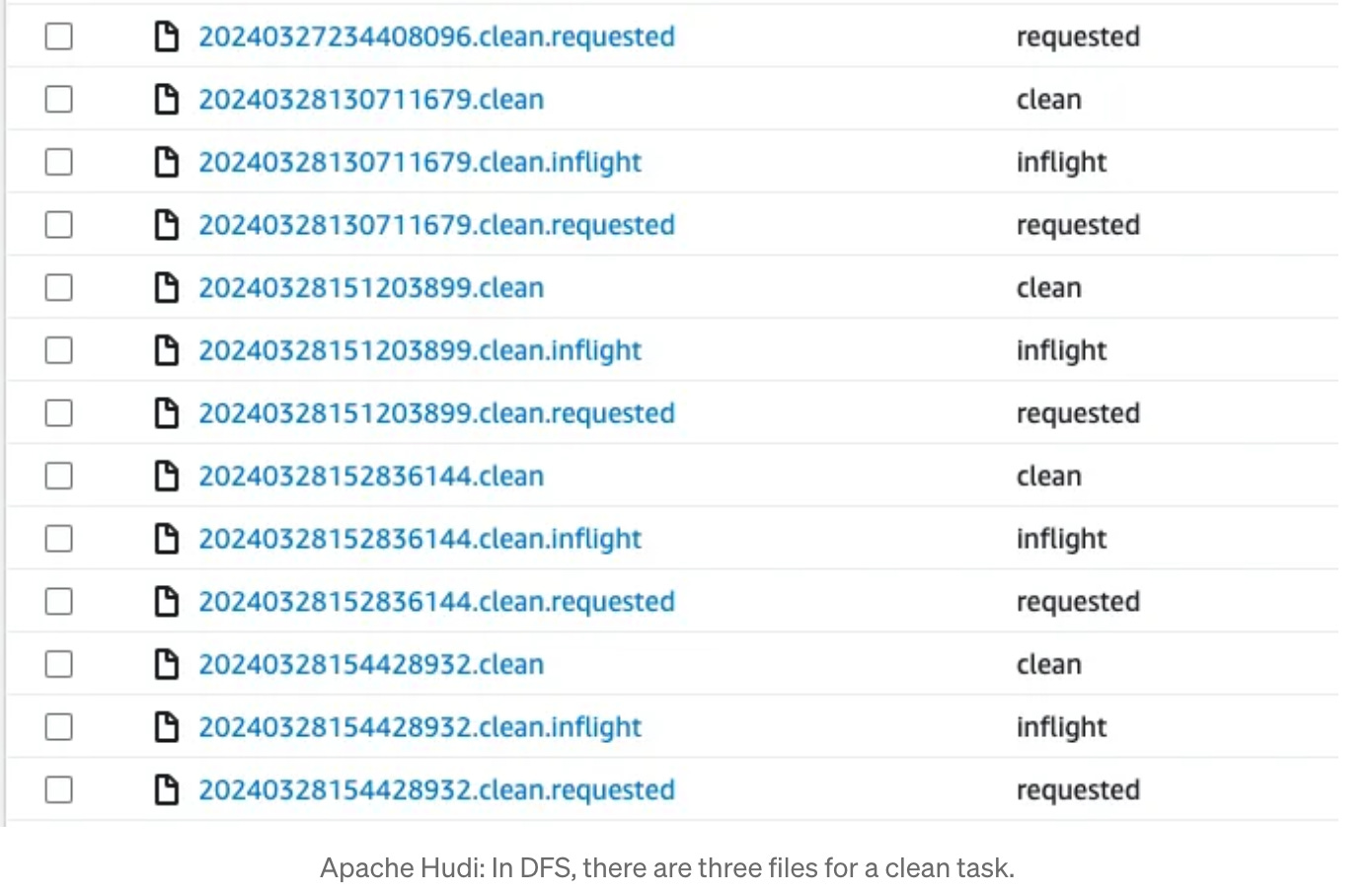
This blog details the author's troubleshooting experience with Apache Hudi, particularly focusing on performance issues related to Hudi Cleaners. The author delves into the mechanics of Hudi's cleaning process, which helps manage storage by removing obsolete data files. By examining the Avro-formatted clean request files, Gatsby provides insights into the data structure and offers a practical solution through a custom script for loading and analyzing these files.
Becoming "One" - the upcoming Hudi 1.0 highlights - Shiyan Xu | Onehouse
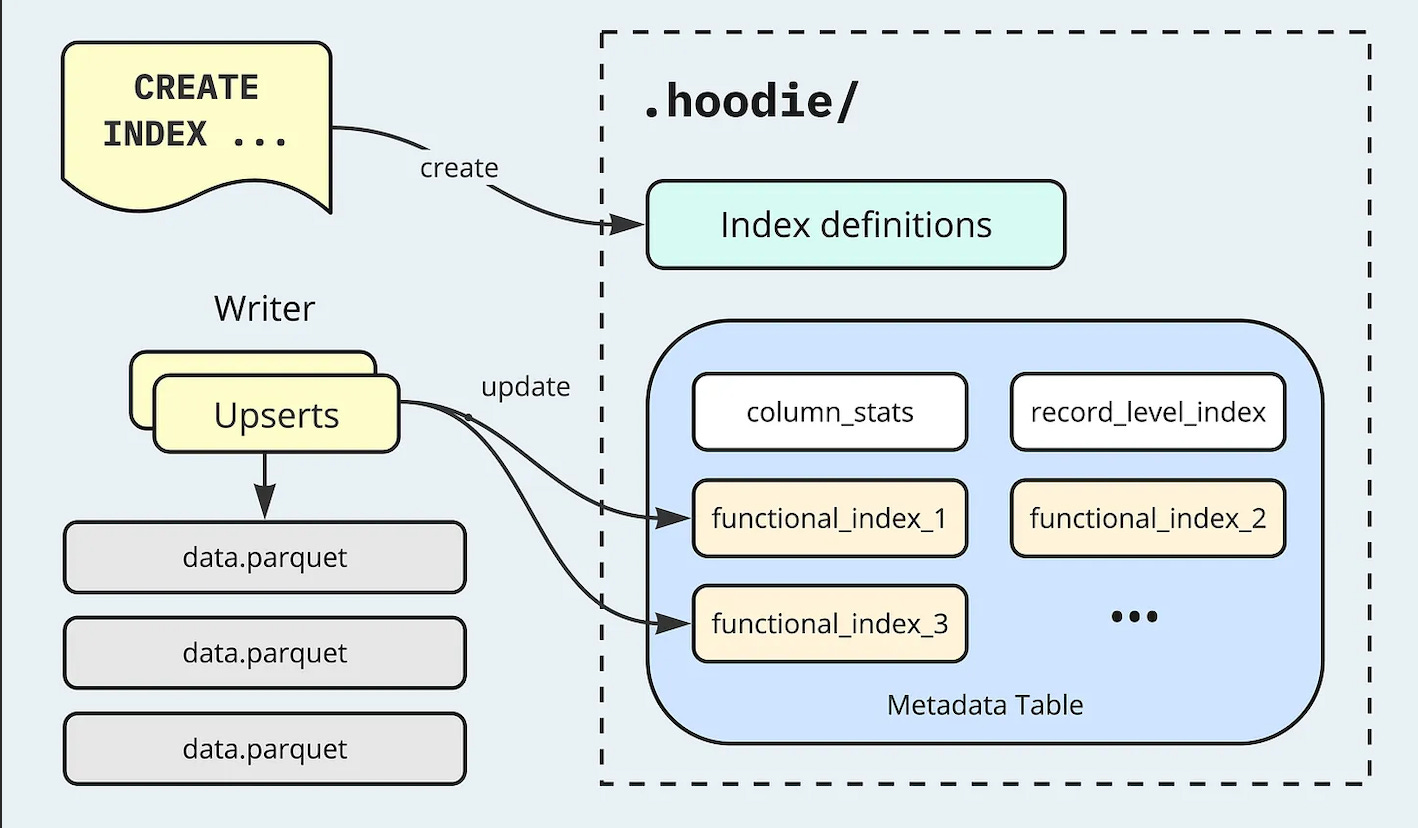
The final piece in Shiyan Xu’s ten-part series provides an in-depth look at Apache Hudi's evolution, focusing on the significant enhancements introduced in the upcoming 1.0 release. It revisits key components of Hudi’s transactional database layer, programming API, and user interface, which makes Hudi a robust data lakehouse platform. Most importantly, the blog highlights new design elements such as the LSM Tree Timeline, Non-Blocking Concurrency Control, File Group Reader & Writer, and the Functional Index, showcasing how they contribute to improved efficiency and throughput for users.
📱Socials
We're thrilled to see the rapid growth of the Apache Hudi community across social media platforms. Recently, it achieved a significant milestone, surpassing 5,000 followers! 🎉

Here are some of the interesting posts from the community.
Amazon Web Services (AWS) & Apache Hudi Pipeline
Shashank goes over the flow of building a near real-time data pipeline using Apache Hudi, Apache Flink and AWS stack (Aurora, Amazon MSK, EMR, Glue, Athena).
How Robinhood built a streaming lakehouse - Summary
This post by Cheng Tan summarizes a talk from Robinhood at Data+AI Summit 2022. It discusses the flexibility of choosing different table types in Apache Hudi and automation capabilities to manage large datasets efficiently. Robinhood enhances data scalability and consistency with automated onboarding and real-time data freshness using Change Data Capture (CDC), striking a balance between transactional and analytical processing needs.
File Listings in Cloud Data Lakes like Amazon S3 with Apache Hudi
When reading & writing data, file listing operations are essential to get the current view of the file system. In scenarios with extensive data volumes, listing all the files can turn into a performance bottleneck. Especially, with cloud object stores like AWS S3, an excessive volume of file listing calls may lead to rate limiting (throttling) owing to predefined request caps. Read how Hudi helps.
Learn how to use Apache Hudi with Apache Kyuubi
Apache Kyuubi is a distributed and multi-tenant gateway to provide serverless SQL on Data Warehouses and Lakehouses. In this post, Soumil provides configuration details to connect Apache Hudi tables with Kyuubi and perform various operations.
Project Updates

GitHub ❤️⭐️ https://github.com/apache/hudi
[IMPROVEMENT] A new PR has been merged that changes the default payload type to HOODIE_AVRO_DEFAULT from the current OVERWRITE_LATEST.
Hudi HTTP write commit callback URLs don't support passing the custom headers as of now. This new PR supports the addition of custom headers via a new configuration parameter, ‘hoodie.write.commit.callback.http.custom.headers’ in HoodieWriteConfig, allowing users to specify headers in a structured format.
A new parameter, --ignore-checkpoint is added to the HoodieStreamer. This parameter allows users to bypass the checkpoint mechanism when set.
This PR modifies the default cleaner behaviour to prevent multiple cleaner plans when the metadata table is enabled. A new cleaner plan will only be scheduled if there is no inflight plan, setting the default of hoodie.clean.allow.multiple to False.
Community Events
Past Events

Last month concluded the Hudi-Presto workshop, featuring a hands-on lab designed to assist data engineers and architects in initiating their journey with an open lakehouse architecture. This architecture utilizes Hudi as the lakehouse platform and Presto as the compute engine. The workshop comprehensively covered key capabilities of Hudi, including clustering and metadata table functionalities. Access the code repository here.
Upcoming Events (in May)

The Hudi community, in collaboration with Navi Technologies, is hosting an in-person meetup in Bangalore, India. Join on May 11th, 2024, to hear from data teams implementing and building Hudi to solve some of the most critical challenges in real-time data ingestion, improve time-to-insight, and discuss innovations in Hudi’s transactional layer (with Hudi 1.0) that empower critical capabilities in lakehouse architecture. Register here.
Hudi Resources
Getting started 🏁
If you are just getting started with Apache Hudi, here are some quick guides to delve into the practical aspects.
Official docs 📗
Join Slack 🤝
Discuss issues, help others & learn from the community. Our Slack channel is a home to 4000+ Hudi users.
Socials 📱
Join our social channels to be in the know about deep technical concepts to tips & tricks and interesting things happening the community.
Twitter/X: https://twitter.com/apachehudi
Weekly Office Hours 💼
Hudi PMC members/committers will hold office hours to help answer questions interactively, on a first-come first-serve basis. This is a great opportunity to bring any doubts.
Interested in Contributing to Hudi?👨🏻💻
Apache Hudi community welcomes contributions from anyone! Here are few ways, you can get involved.
Rest of the Data Ecosystem
Lakehouse Analytics with Hudi and Iceberg using XTable & Dremio - Dipankar Mazumdar, Alex Merced
Open Lakes, Not Walled Gardens - Raghu Ramakrishnan, Josh Caplan (Microsoft)
Flink SQL—Misconfiguration, Misunderstanding, and Mishaps - Robin Moffatt
[Research Paper] Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database - Amazon Web Services
Have any feedback on documentation, content ideas or the project? Drop us a message!