


Hudi Newsletter#1: March-2024


Hello, Apache Hudi enthusiasts!
Welcome to the first edition of Hudi Newsletter, your monthly digest for all things Apache Hudi. This new newsletter is brought to you by Onehouse.ai with the aim of bringing the vibrant Hudi community even closer together.
Why “Hudi Newsletter” now?
The Apache Hudi project has grown exponentially, becoming a cornerstone for engineers and architects looking to build universal data lakehouse platforms. With this rapid growth, there’s always something new that our diverse community is working on. In each edition of “Hudi Newsletter”, we will reflect on everything that has happened in the Hudi world in the past month & look at some of the interesting future updates to keep users and enthusiasts informed.
Here's what you can expect from the Hudi Newsletter:
Project Updates
Community Highlights
Ecosystem Updates
Upcoming Events
Curated Hudi Resources
Let’s get started!
Project Updates

GitHub ❤️⭐️ https://github.com/apache/hudi
A new payload OverwriteWithGreaterRecordPayload is added to preserve the earlier version when ordering fields are equal between the incoming and existing records.
Three new configs were added to support parallel listing when doing meta-sync to Glue catalog.
hoodie.datasource.meta.sync.glue.all_partitions_read_parallelism
hoodie.datasource.meta.sync.glue.changed_partitions_read_parallelism
hoodie.datasource.meta.sync.glue.partition_change_parallelism
Added a new MetricsReporter implementation org.apache.hudi.metrics.m3.M3MetricsReporter which emits metrics to M3. Users using https://m3db.io can enable reporting metrics to M3 by setting hoodie.metrics.reporter.type as M3 and their corresponding host address/port in hoodie.metrics.m3.host / hoodie.metrics.m3.port
When writing Apache Flink TIMESTAMP data, we can now use local timezone. Thanks to this PR.
Community Blogs/Socials
Blogs
Navigating the Future: The Evolutionary Journey of Upstox’s Data Platform - Manish Gaurav | Upstox
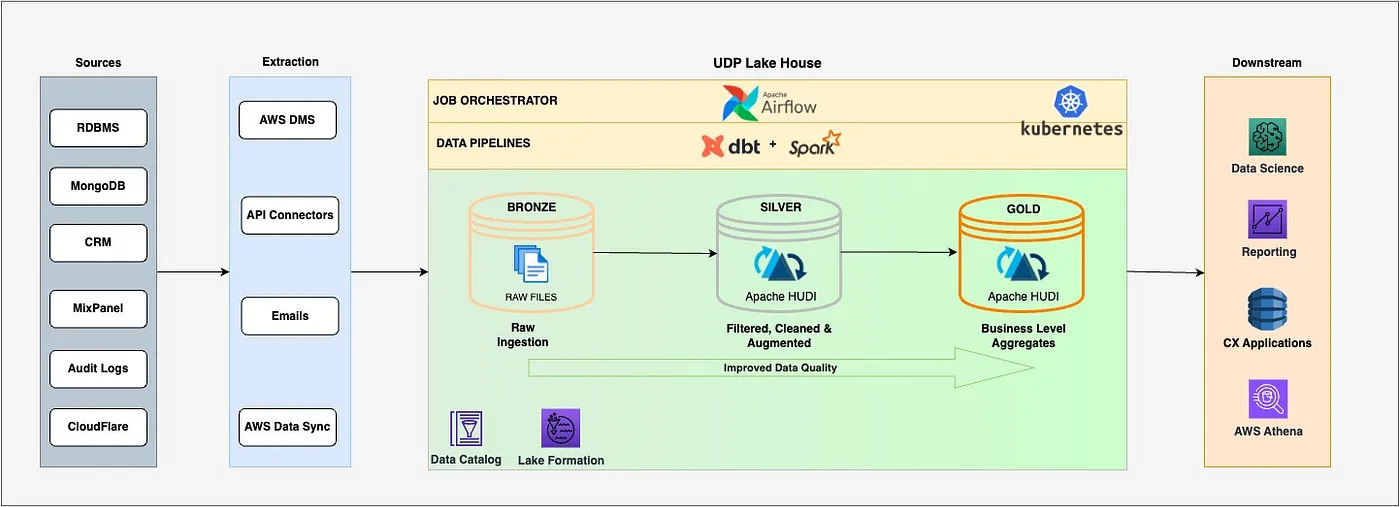
In this blog, Manish details the evolution of Upstox’s Data Platform (UDP) and how they tackle the challenges around scalability and cost while addressing other fundamental problems such as ACID support, Data Lake management, data processing, data access patterns, etc., on the data lake using open source technologies like Apache Hudi, Airflow, and DBT. The blog focuses on Hudi’s cleaner service, auto file sizing, and indexing capabilities that allowed them to deal with storage costs, small file problems, and faster updates.
Cost Optimization Strategies for scalable Data Lakehouse - Halodoc Engineering
Halodoc discusses some of the critical strategies for optimizing costs in a scalable Data Lakehouse architecture. The blog highlights the importance of managing S3 non-current versions, cleaning up incomplete multipart uploads, and keeping a check on S3 API costs by using Apache Hudi features like partition pruning, metadata table indices, and cleaner/archival services. Implementing these strategies led to significant savings for them: a 66.3% decrease in S3 API requests, a 41.5% cut in S3 costs, and a 34.2% reduction in EMR costs.
Enabling near real-time data analytics on the data lake - Shi Kai Ng, Shuguang Xiang | Grab Engineering
Grab’s Engineering team elaborates on their approach to enabling near-real-time data analytics on their data lake. They detail the transition from traditional data lakes to using Apache Hudi table format for minimal data latency, thereby enabling faster data access to analysts. The improvements have enabled fresher business metrics and quicker fraud detection, showcasing the impact on operational efficiency and response times.
HoodieStreamer - a "Swiss Army knife" for ingestion - Shiyan Xu | Onehouse
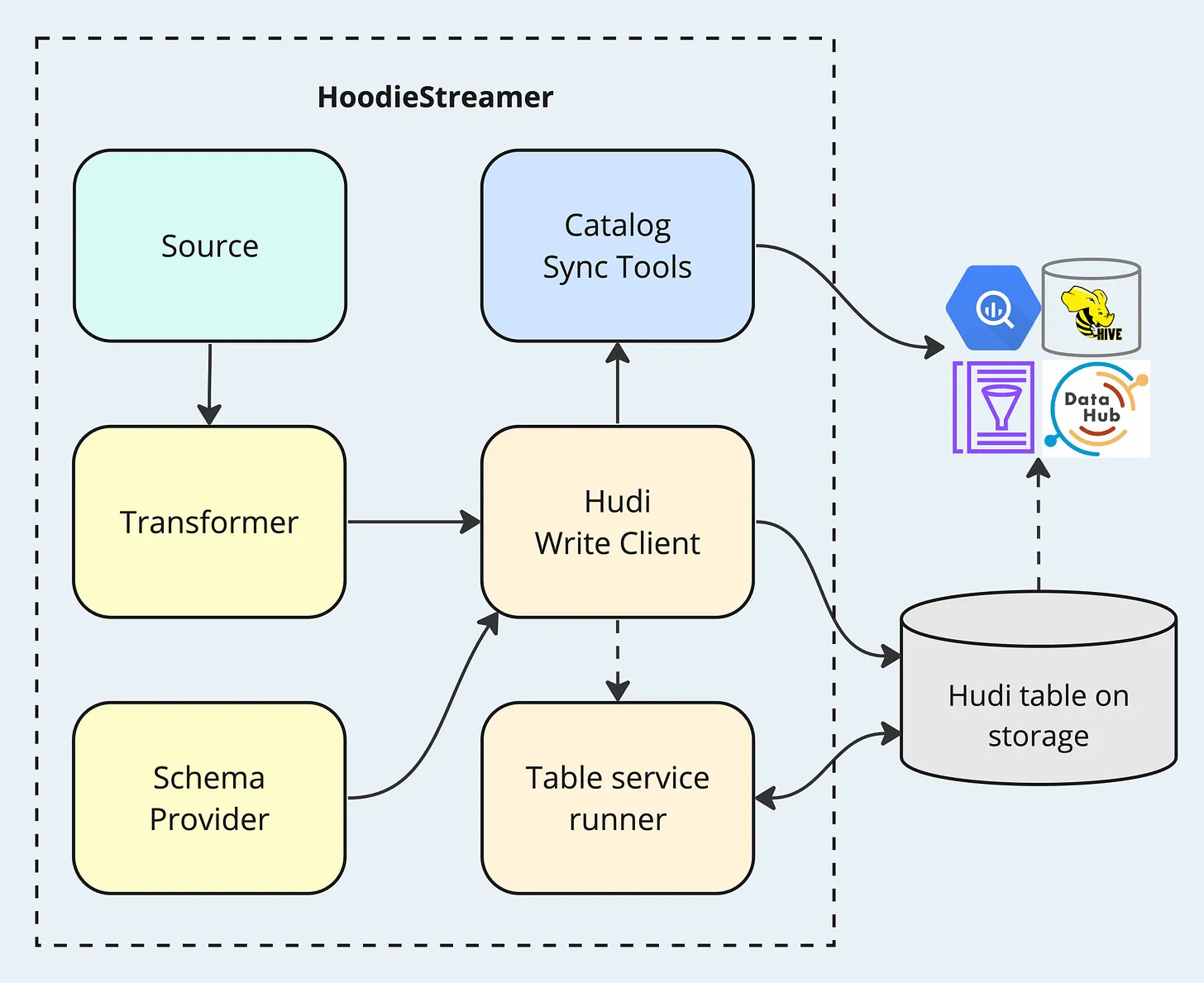
This ninth piece in a ten-part series offers an in-depth look at HoodieStreamer, a data ingestion tool closely coupled with Hudi’s lakehouse platform that allows users to configure source data, define schemas, schedule table services, keep data catalogs in sync, amongst others. The blog breaks down the various technical components of HoodieStreamer and is a must read for users who want to understand the tool’s capabilities in depth.
Open Table Format : Apache Hudi (Hadoop Upserts Deletes and Incrementals) - Vivek Alex | Samta.ai

This introductory blog dives into Apache Hudi's lakehouse platform and its comprehensive components beyond mere table formats. Vivek notes, "While the functionality provided by a table format is just one layer in the Hudi software stack, Hudi encompasses a complete system with tools that facilitate smarter data management." It discusses the array of components in the Hudi stack and illustrates how features like record-level updates and incremental processing not only significantly cut down on compute resources but also offer a more streamlined method for handling data within data lakes.
Socials
Data Engineer Interview Experience - Apache Hudi with Spark
Great set of Data Engineering interview questions with Apache Hudi & Spark by Anurag.
Apache Hudi for Data Engineers
Shashank talks about some of the critical challenges (data freshness, managing pipelines, data reliability) addressed by Apache Hudi with capabilities like faster updates/deletes, time travel, etc. in this post.
Problems in a Data Lakehouse & how Hudi addresses them
What are some of the problems you start to see when you move forth from POC to Production with a Lakehouse architecture? The post touches upon things like small file issues, S3 object store throttling, and data co-locality and how Hudi tackles these.
Mastering Incremental ETL with DeltaStreamer and SQL-Based Transformer
In this blog post, Soumil delves into the realm of Incremental ETL using DeltaStreamer and SQL-Based Transformer, focusing on joining Hudi tables with other Glue tables to build denormalized Hudi tables.
Hudi in the Ecosystem
Modern Datalakes with Hudi, MinIO, and HMS - MinIO

In this hands-on tutorial, Brenna Buuck from MinIO demonstrates how to integrate a Hive Metastore (HMS) Catalog with Apache Hudi on top of a MinIO data lake. The repo can be cloned from here.
Combine Transactional Integrity and Data Lake Operations with YugabyteDB and Apache Hudi - YugaByteDB

The YugaByteDB team discusses the combined benefits of using it with Hudi for transactional integrity and efficient data lake operations. The integration benefits from Hudi’s ability to efficiently manage large-scale data in data lakes, along with YugaByteDB’s robust transactional capabilities.
How to use StarRocks and Apache Hudi to build a robust open data lakehouse architecture - StarRocks
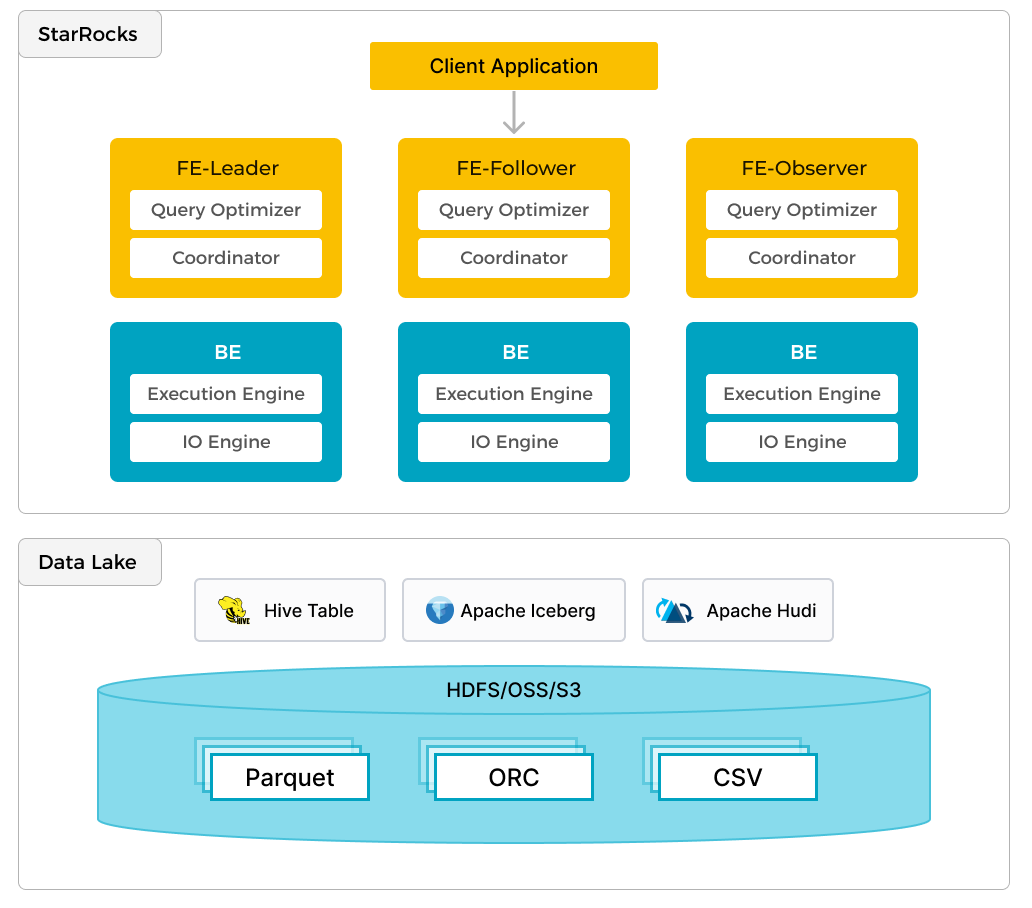
StarRocks is an OLAP data warehouse (MPP) that supports real-time and highly concurrent data analysis. It also enables analysis on open table formats such as Apache Hudi in data lakes. This detailed tutorial serves as a go-to guide for users looking to try their hand at using Hudi with StarRocks' compute.
Latest Community Sync & Hudi Live Sessions

Our Journey with Apache Hudi: Lessons Learned and the Road Ahead - Funding Circle
Why Apache Hudi + Apache Doris is an ace for data lake analytics
Boost Presto query speeds with Hudi's metadata table & clustering service
Tip of the Month
Have specific questions on Hudi? Book a 1-1 consultation with Hudi PMC for dedicated discussion and tips
Upcoming Events in April
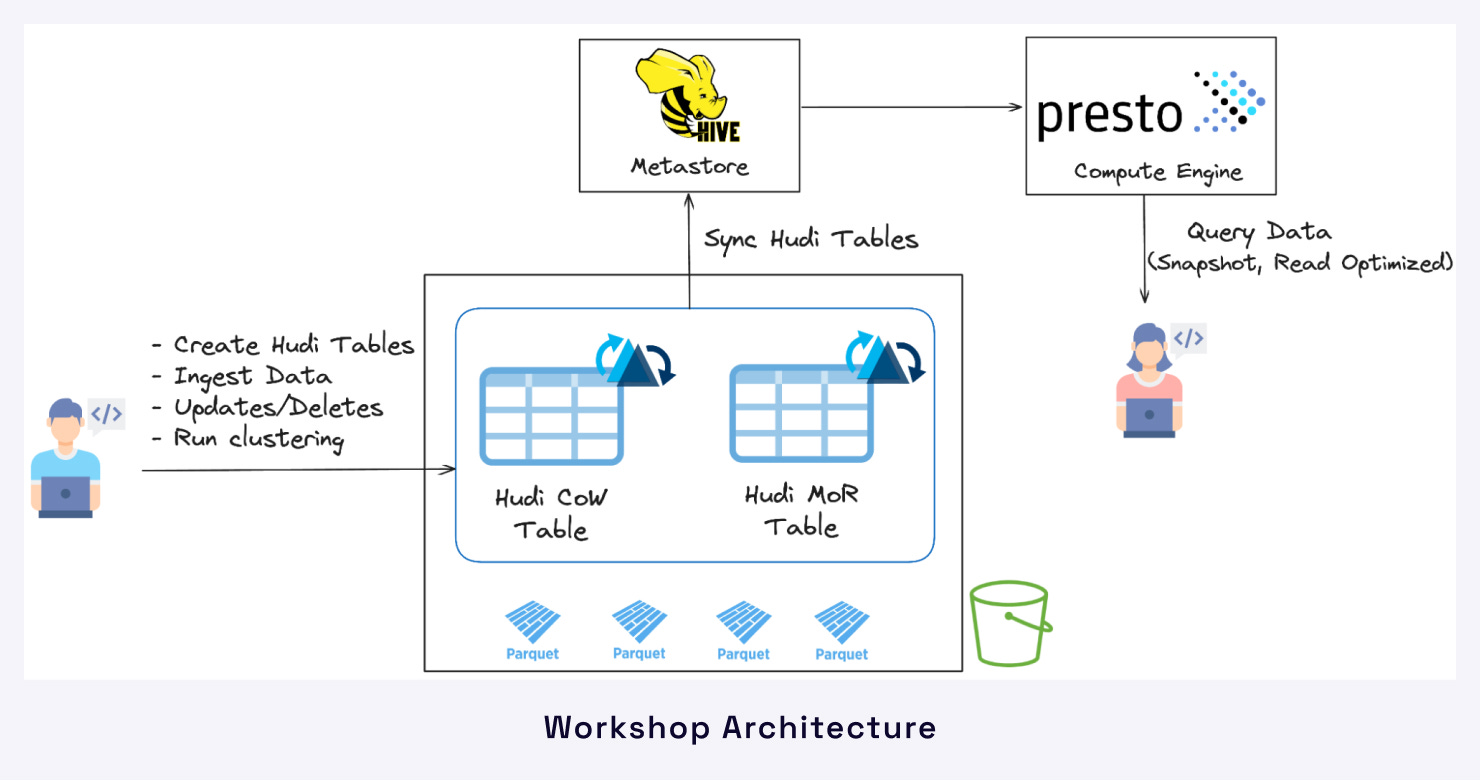
Building an Open lakehouse on AWS S3 with Apache Hudi & PrestoDB - Led by Hudi and Presto Contributors, this workshop happening on 24th April (9 AM - 12 PM PST) will help attendees understand how to build an open lakehouse architecture using Hudi as the table format on S3 data lake and leverage Presto as the compute engine for ad hoc, interactive analytics at scale.
Hudi Resources
Getting started 🏁
If you are just getting started with Apache Hudi, here are some quick guides to delve into the practical aspects.
Apache Spark: https://hudi.apache.org/docs/next/quick-start-guide
Apache Flink: https://hudi.apache.org/docs/next/flink-quick-start-guide
Docker Demo: https://hudi.apache.org/docs/next/docker_demo
Official docs 📗
Join Slack 🤝
Discuss issues, help others & learn from the community. Our Slack channel is a home to 4000+ Hudi users.
Socials 📱
Join our social channels to be in the know about deep technical concepts to tips & tricks and interesting things happening the community.
Twitter/X: https://twitter.com/apachehudi
Weekly Office Hours 💼
Hudi PMC members/committers will hold office hours to help answer questions interactively, on a first-come first-serve basis. This is a great opportunity to bring any doubts.
Interested in Contributing to Hudi?👨🏻💻
Apache Hudi community welcomes contributions from anyone! Here are few ways, you can get involved.
Rest of the Data Ecosystem
OneTable is now “Apache XTable™ (Incubating)” - Dipankar Mazumdar, JB Onofré
E-commerce Funnel Analysis with StarRocks: 87 Million Records, Apache Hudi, Apache Iceberg, Delta Lake - Albert Wong
Databases Are Commodities. Now What? - Chris Riccomini
Making Most Recent Value Queries Hundreds of Times Faster - Nga Tran, Andrew Lamb
[Paper: VLDB 2024] - POLAR: Adaptive and Non-invasive Join Order Selection via Plans of Least Resistance - Justin et al.
Have any feedback on documentation, content ideas or the project? Drop us a message!